【MoE 论文 其一】MoE领域的重要里程碑
MoE在自然语言处理中的开端
(Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer)[https://arxiv.org/abs/1701.06538]
背景: 学术界都在卷RNN,当时比较火的应该是LSTM,google这篇论文首次将参数规模扩大到137B这个级别,在当时也是十分惊人的
文中提出的挑战:
- GPU不擅长逻辑运算,需要在gate上有所设计 (lstm也不是if...else实现啊)
- 条件计算减少了网络中条件活动块的批量大小
- 网络带宽问题
- 需要新的loss function 保证每个块的稀疏度水平与负载均衡
- BATCH SIZE 问题
模型结构
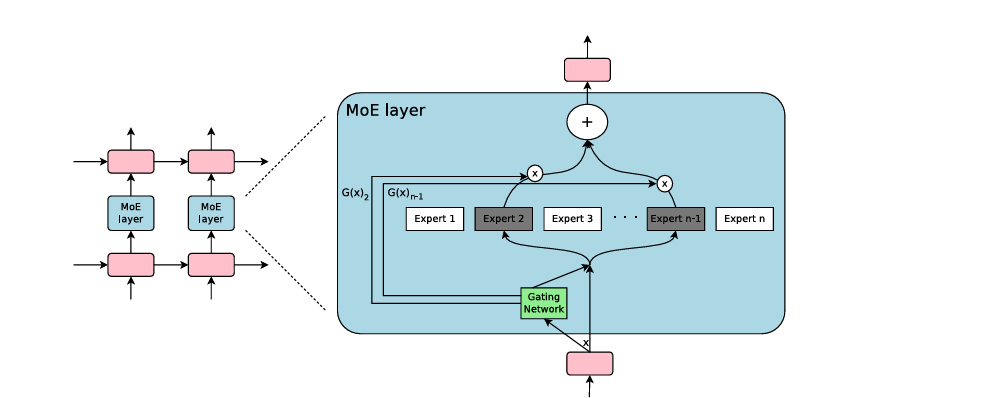
moe结构
⚠️ RNN是自循环的结构,MoE设计上也是自动更新参数的(左侧是根据时间展开)
算法改进

引入top_k 与噪声
- 在传统的
G(x)中加入了top_K与噪声H - top_k 为网络带来了稀疏性
- 噪声对应是解决专家太多,出现负载均衡的问题,在后面的 loss function 中提到
性能问题
大的batch-size能提高效率,但选择专家的操作会让分配到的batch变小,文中提出了数据并行性和模型并行性的方法,但文章中对于RNN的并行方法与现在的transformer不同,不作更多地解读。
专家的均衡负载
门控网络会偏向于少数几个专家,导致训练的不平衡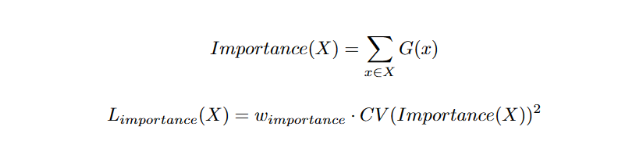
L_importance
- 定义了专家的重要性,提出一种软约束的方法,通过一个额外的 loss function, 鼓励所有专家的重要性趋于均衡
- 引入了第二个 loss function,平衡分配数据。针对数据量的差异问题
2.1 通过一个函数估计了第
i个专家使用数据的概率
文章的一下实验数据
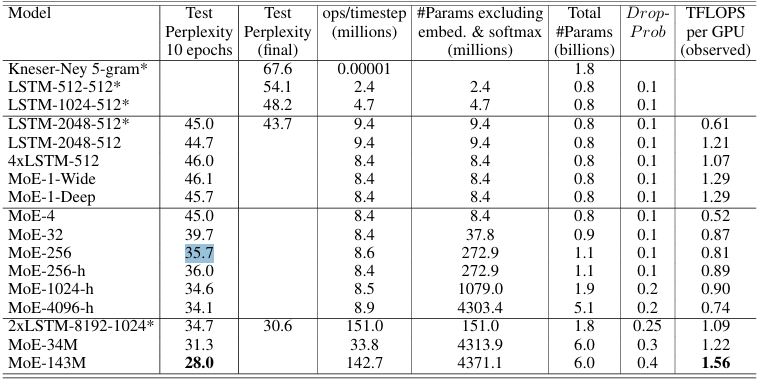
专家数据不是越多越好